1 Greedy Decoding
- Greedy Decoding
- seq2seq model의 decoder의 각 time step마다 가장 높은 확률값을 가지는 단어 하나만을 output으로 return하는 방식
- ‘단어’ → 문장 전체에 대한 확률을 고려하는 것이 아니라, 각 time step에서의 단어에 대한 확률만을 고려함
- ‘하나’ → 한 번 결정된 output을 취소할 수 없어, 한 번 잘못된 output을 생성하면 잘못 생성한대로 그 이후 time step에 계속하여 영향을 미치게 됨
- seq2seq model의 decoder의 각 time step마다 가장 높은 확률값을 가지는 단어 하나만을 output으로 return하는 방식
2 Exhaustive Search
- Exhaustive Search
- 가능한 모든 경우의 수를 고려하여 최적해를 찾는 방식
- Exhaustive Search의 작동 방식
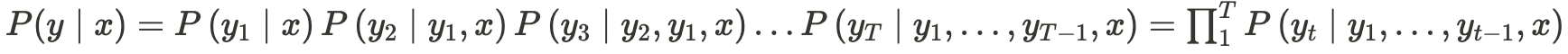
- vocabulary size가 V이고, time step이 t까지일 때 P(y | x)가 최대인 y를 찾기 위해서는 V^t번의 연산을 필요로 함
- → too expensive
3 Beam Search
- Beam Search
- decoder의 각 time step에서 가장 가능성이 높은 k개의 partial translation (=hypothesis)을 추적하는 방식
- Greedy Decoding과 Exhaustive Search의 타협점
- : 최적해에 대한 보장은 없지만, Exhaustive Search보다 효율적임
- decoder의 각 time step에서 가장 가능성이 높은 k개의 partial translation (=hypothesis)을 추적하는 방식
- Beam Search의 작동 방식
- 매 time step마다 score가 높은 k개의 hypothesis를 추적

- stopping criterion
- greedy decoding에서는 model이 <END> token을 생성할 때까지 decoding을 진행하는데,
- beam search decoding에서는 각각의 hypothesis가 각각 다른 time step에서 <END> token을 생성할 수 있음
- <END> token이 생성된 hypothesis (= complete hypothesis)는 저장해둠
- 일정 time step에 다다르거나 / 일정 개수의 complete hypothesis가 생성될 때까지 beam search
- 최종 output 선택
- hypothesis의 score은 긴 hypothesis에게 불리하므로, 최종 output을 선택할 때에는 hypothesis의 길이로 normalize한 score을 사용

'NLP > Concept' 카테고리의 다른 글
| [NLP] Machine Reading Comprehension (1) | 2023.06.06 |
|---|---|
| [NLP] BERT basic (0) | 2023.05.05 |
| [NLP] Seq2Seq with Attention (0) | 2023.04.03 |
| [NLP] Sequential Model (0) | 2023.04.03 |
| [NLP] Word Embedding (0) | 2023.04.03 |




댓글