[Math for AI] joint pdf와 likelihood function은 같은 식을 다르게 해석한 것에 불과할까?
Question
수리통계학 문제를 풀다보면 likelihood function을 사용하는 문제에서 대부분 joint pdf를 이용하여 likelihood를 구한다. 이는 likelihood와 joint pdf가 같은 식임을 의미하는데, 그렇다면 joint pdf와 likelihood function은 같은 식을 다르게 해석한 것에 불과할까?
joint pdf와 likelihood function
- joint pdf
- 특정 모수가 주어졌을 때, 데이터들이 나타날 확률

- likelihood function
- 데이터들이 주어졌을 때, 특정 모수가 해당 데이터를 나타낼 확률
- → 어떠한 데이터들이 관찰되었을 때, 그 데이터들이 어떤 분포로부터 왔는지 알고싶을 때 사용
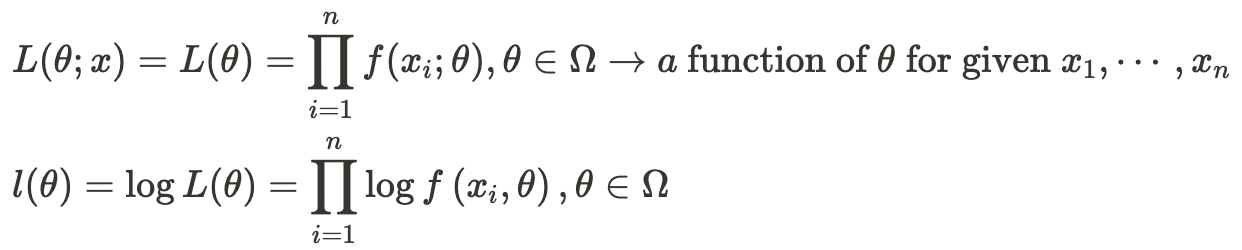
같은 식이지만 다르게 해석되는 joint pdf와 likelihood function

0부터 0.5 범위의 선 위에 어떤 점 x를 랜덤하게 찍는다고 가정해보자.
그 때, 이 x가 0.3 이상의 범위에 찍힐 확률은 0.4이다. (P(0.3 ≤ x ≤ 0.5) = 0.4)
또한, 이 x가 0 이상의 범위에 찍힐 확률은 1이다. 주어진 범위의 어느 곳에 찍혀도 0 이상이라는 조건을 만족하기 때문이다.
위의 이미지는 위에서 말한 상황에 대한 pdf이다. 가로 0.5 * 세로 2 = 1이므로 확률의 합이 1임을 확인할 수 있다.
이 때, 위에서처럼 범위가 아닌 특정 ‘값’에서의 pdf를 살펴보자.
x=0.3일때의 pdf는 2이다. 이것을 ‘x가 0.3이 될 확률은 2이다’라고 말할 수 있을까? 그렇지 않다. 연속확률변수가 특정 값에서 가지는 확률은 0이기 때문이다.
이것이 joint pdf와 likelihood가 다르게 해석되는 지점이다.
joint pdf에서 특정 값에 대한 함숫값은 별로 의미를 가지지 못한다. 어차피 특정 값에서의 확률은 0이기 때문이다.
하지만 likelihood의 관점에서는, 특정 값에서의 함숫값이 더 높은 분포가 해당 값을 더 잘 나타내는 분포가 될 수 있을 것이다.
Answer
joint pdf와 likelihood function은 같은 식을 다르게 해석한 것이다.
joint pdf는 특정 분포가 주어졌을 때, 그 분포로부터 어떠한 데이터들이 관찰될 확률을 나타내는 반면, likelihood function은 데이터들이 관찰되었을 때, 특정 분포가 그 데이터들을 나타낼 확률을 나타낸다.
고등학생 때 확률질량함수를 처음 배우면서, 한 점에서의 확률값은 0이라는 것과 그래프 상에서 확률질량함수가 함숫값이 가지는 것이 모순적이라고 생각했었는데, 확률질량함수의 함숫값이 가지는 의미에 대해 생각해볼 수 있어서 재미있는 탐구였다고 생각한다 !