NLP/Papers
[NLP Paper] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019, BERT)
iamzieun
2023. 5. 8. 00:20
본 포스팅은 논문 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding을 읽고 요약한 글입니다.
https://arxiv.org/abs/1810.04805
Abstract
- label이 없는 text 데이터에 대하여 모든 layer에서 양방향의 문맥을 모두 고려한 deep bidirectional representation을 pre-train
- pre-train된 BERT는 모델 구조의 큰 변경 없이 output layer을 하나만 더 추가함으로써 여러 nlp task에 맞게 fine-tuning이 가능
1 Introduction
- 언어 모델의 pre-training은 많은 nlp task의 성능 향상에 기여함
- sentence-level tasks (ex. natural language inference, phraphrasing)
- 문장들을 전체적으로 분석함으로써 문장들 사이의 관계를 예측
- token-level tasks (ex. named entity recognition, question answering)
- token 단위의 세부적인 output을 생성
- sentence-level tasks (ex. natural language inference, phraphrasing)
- pre-trained language representation을 세부적인 task에 적용하는 전략
- feature-based approach (ex. ELMO)
- task-specific architecture 사용
- pre-train된 representation는 추가적인 feature로 사용
- task-specific architecture 사용
- fine-tuning approach (ex. GPT)
- task-specific parameter를 최소화
- 모든 pre-train된 parameter를 세부적인 task에 맞게 fine-tuning
- unidirectionality constraint: 위 전략들을 사용하는 기존의 모델들은 unidirectional(단방향)이므로, pre-training에 사용할 architecture의 선택에 제약이 가해짐
- ex. GPT는 left-to-right architecture를 사용 → Transformer의 self-attention layer에서 모든 token들은 자신 이전의 token에만 접근 가능
- feature-based approach (ex. ELMO)
- BERT (fine-tuning approach 채택)
- masked language model(MLM) pretraining objective를 통해 unidirectionality constraint를 해결
- 문장에서 일부 단어를 masking한 후, masking한 부분을 맞추도록 학습시킴으로써 representation이 양방향에서의 문맥을 포함하도록 함
- next sentence prediction을 통해 text-pair representation을 pre-train
- masked language model(MLM) pretraining objective를 통해 unidirectionality constraint를 해결
2 Related Work

2.1 Unsupervised Feature-based Approaches
- pre-training representations of words
- pre-train word embedding vectors
- left-to-right 언어 모델
- 잘못된 단어들로부터 올바른 단어 구별
- pre-train sentence representations
- 다음으로 올 문장 후보들 순위 매기기
- 이전 문장에 대한 representation이 주어졌을 때 다음 문장 생성
- noise가 껴있는 문장 복원
- pre-train word embedding vectors
- ELMO
- left-to-right 모델과 right-to-left 모델에서 context-sensitive representation을 추출
→ 생성한 contextual word embedding + task-specific architecture
2.2 Unsupervised Fine-tuning Approaches
- unlabeld text를 이용하여 encoder를 pre-train한 후 → 세부적인 task에 맞게 fine-tuning
- → (fine-tuning 시에) 처음부터 학습해야하는 parameter가 거의 없다는 장점
- GPT
- pre-training을 위해 left-to-right 모델과 auto-encoder 사용
feature-based approach와 fine-tuning approach는 모두 model의 output을 활용한다. 다만, feature-based approach에서는 fine-tuning 시 feature를 추출하는 pre-trained model은 더 이상 학습시키지 않는 반면, fine-tuning approach는 feature를 추출하는 pre-trained model을 fine-tuning함으로써 model의 parameter를 업데이트한다.
2.3 Transfer Learning from Supervised Data
- large datasets을 통한 supervised task를 transfer learning
3 BERT
- pre-training
- unlabeled data로 pre-training
- fine-tuning
- pre-trained parameter로 초기화 → dowmstream task를 위한 labeled data를 사용하여 fine-tuning
⇒ 다른 task라 하더라도 모두 같은 architecture를 기반으로 함
- pre-trained architecture와 dowmstream task에 맞춰진 최종적인 architecture간에는 minimal difference만이 존재함
Model Architecture

- multi-layer bidirectional Transformer encoder
- model size
- BERT base: L=12, H=768, A=12, Total Parameters=110M
- BERT large: L=24, H=1024, A=16, Total Parameters=340M
- L: number of layers
- H: hidden size
- A: number of self-attention heads
Input/Output Representations

- input representation
- input embedding = token embeddings + segment embeddings + position embeddings
- token sequence (=’sentence’)
- 한 문장 또는 한 쌍의 문장
- 한 쌍의 문장이 한 sequence에 포함된 경우,
- 두 문장 사이에 [SEP] token을 넣고
- segments embedding을 통해 각각의 token이 어떤 문장에 속하는지를 나타냄으로써 두 문장을 구분
- embedding 방식
- WordPiece embedding
- vocabulary: 30000개의 token으로 구성
- 모든 sequence의 첫 번째 token은 [CLS]
- [CLS]의 final hidden state는 classification에서 전체 sequence에 대한 압축적인 representation으로 사용
- WordPiece embedding
- output representation
- [CLS] token의 final hidden vector: C
- [CLS] token을 제외한 input token의 final hidden vector: T
3.1 Pre-training BERT
- MLM과 NSP의 두 가지 unsupervised task를 통해 pre-train
- pre-train에 사용한 데이터셋
- BooksCorpus (800M words)
- English Wikipedia (2500M words)
Task #1: Masked LM (MLM)
- 양방향의 conditioning을 통해 word representation을 만드는 과정에서는 간접적으로 자기 자신을 보게 된다는 문제가 있음
- → 이를 예방하기 위해 각 sequence에서 15%의 token을 masking 처리한 후 → mask token의 final hidden vector가 output softmax의 input으로 들어가서 원래 token과 얼마나 유사한지 판단
- MLM을 통한 pre-training과 fine-tuning과정 사이의 괴리를 메꾸기 위해 (fine-tuning시에는 mask token이 없으니까)
- 선택된 15%의 token 중
- 80%는 [MASK] token으로 대체
- ex. my dog is hairy → my dog is [MASK]
- 10%는 random token으로 대체
- ex. my dog is hairy → my dog is apple
- 10%는 바꾸지 않음 → representation을 원래 단어에 편향되게끔 하기 위함
- ex. my dog is hairy → my dog is hairy
- 80%는 [MASK] token으로 대체
- 이러한 방식으로 만든 15%의 token의 fianl hidden vector에 대하여 cross entropy loss를 적용함으로써 기존 token과 유사한 vector가 생성되게끔 함
- 선택된 15%의 token 중
Task #2: Next Sentence Prediction (NSP)
- NLI 및 QA와 같이 두 문장 사이의 관계를 이해하는 모델을 학습하기 위해 next sentence prediction task에 맞게 pre-train
- pre-train에 사용될 데이터셋의 sentence A와 sentence B를 선택할 때,
- 50%는 실제로 sentence A의 다음 문장을 sentence B로 선택 (label: IsNext)
- 50%는 corpus로부터 임의의 문장을 sentence B로 선택 (label: NotNext)
3.2 Fine-tuning BERT
- Transformer의 self-attention mechanism에 1) 각각의 문장을 독립적으로 encode하고 2) bidirectional cross attention을 적용하는 과정이 모두 포함되어 있어서 많은 downstream task에 맞게 fine-tuning 가능
- task에 맞는 input과 output을 BERT에 plug한 후 모든 parameter를 fine-tuning
- input
- pre-train에서 사용한 두 문장(sentence A와 sentence B)으로 구성된 sequence처럼
- phraphrasing에서의 sentence pair
- entailment에서의 hypothesis-premise pair
- question answering에서의 question-passage pair
- text classification 및 sequence tagging에서의 degenerate text-∅ pair로 fine-tuning
- pre-train에서 사용한 두 문장(sentence A와 sentence B)으로 구성된 sequence처럼
- output
- token-level task에서는 token representation이 output layer에 주어짐
- classification에서는 [CLS]의 representation이 output layer에 주어짐
4 Experiments
4.1 GLUE
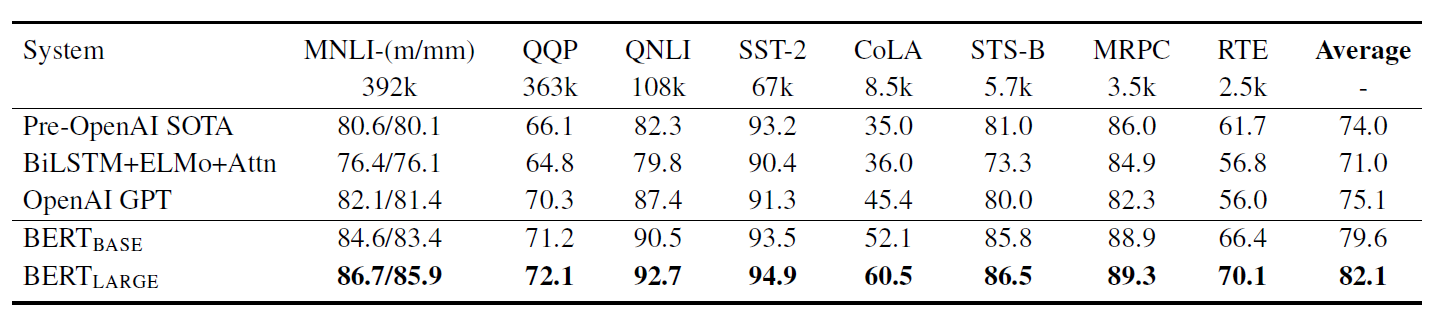
4.2 SQuAD v1.1 / SQuAD v2.0


4.4 SWAG

5 Ablation Studies
5.1 Effect of Pre-training Tasks
- NSP, LSR, BiLSTM에 따른 4개의 모델로 실험
- BERT_Base
- No NSP
- LTR & No NSP
- LTR & No NSP & BiLSTM
- SQuAD에서는 LTR & No NSP에 비해 성능이 향상되었으나, GLUE에서는 성능이 저하됨
5.2 Effect of Model Size
- layer, hidden unit, attention head의 개수를 통해 model size를 다양화
- larger model이 모두 성능이 더 좋음
- 특히 충분한 pre-train이 전제된다면, model의 크기를 키우는 것은 소규모 (데이터)의 task에 대하여도 성능 향상을 보장할 수 있음을 보여줌
5.3 Feature-based Approach with BERT
- feature-based approach의 장점
- 모든 task가 Transformer encoder의 architecture로 쉽게 표현되지는 않으므로, task에 특화된 모델의 architecture의 활용이 강점을 가질 수 있음
- training data의 representation을 한 번만 계산해두고, 그 representation을 활용하여 여러 실험을 해볼 수 있음
- feature-based approach vs fine-tuning approach
- fine-tuning 기법이 더 높은 성능을 보여줌
- 하지만 feature-based approach에서도 높은 성능을 보여주며 BERT의 위력을 보여줌
6 Conclusion
- 충분한 데이터를 통한 unsupervised pre-training은 언어 이해 시스템에 중요하며, 이는 데이터가 적은 task도 pre-trained deep unidirectional architecture로부터 이득을 볼 수 있게 하였다.
- BERT는 이를 deep bidirectional architecture로 generalize하여 하나의 pre-trained model로 많은 NLP task에 적용 가능하게 했다는 점에서 의의를 가진다.